Benchmarking algorithmic reasoning in Gemini models
September 1, 2025 · 1 min read
A GSoC 2025 report: disentangling knowledge, reasoning, and execution in LLMs on scientific tasks, and how performance degrades with algorithmic complexity.
1. Introduction
Evaluating frontier models on scientific tasks presents unique challenges. Success often demands a sophisticated blend of domain-specific knowledge, logical reasoning (identifying a sequence of steps from given information and prior knowledge), and multi-step algorithmic execution. Determining the phase of a material from an X-ray diffraction pattern, for instance, requires domain knowledge such as the HKL rules for various crystal structures; reasoning to infer the necessary steps — identifying the highest peak, computing peak ratios — from the given data; and finally execution, the ability to systematically carry out that plan.
Existing benchmarks frequently conflate these factors, making it difficult to discern whether a model's failure stems from a lack of specialized knowledge or an inability to logically apply or execute that knowledge. This “knowledge gap” often obscures a more fundamental “reasoning gap”[1]. A model might fail a scientific reasoning task for want of facts, or — just as often — it might hold the relevant knowledge but be unable to correctly apply a multi-step algorithm or perform accurate intermediate computations. The inherent complexity of the required algorithmic steps is also routinely overlooked: a task demanding five sequential calculations is fundamentally different from one requiring fifty, even when the underlying scientific principle is identical.
This project introduces a benchmarking approach aimed at those limitations. The primary motivation is to abstract away domain-specific knowledge as much as possible and focus on the model's capacity to execute a series of logical and computational steps — an algorithm — once the problem has been conceptually understood. A second motivation is to systematically evaluate how performance degrades as the algorithmic complexity of a task increases. By introducing a scalable variable within each task, we can precisely control the computational burden and observe the resilience limits of different model architectures and prompting strategies.
The methodology involves:
- Designing a diverse set of ten scientific-algorithmic tasks, each with a known solution complexity that can be parametrically varied.
- Evaluating Gemini-2.5-Flash and Gemini-2.5-Pro, with and without a “thinking” prompting strategy, across varying levels of algorithmic complexity for each task.
- Complementing these evaluations with an analysis of performance when code execution is assumed — i.e., when the model only needs to provide the logic or algorithm that an external interpreter then executes — to further isolate reasoning from direct computation.
The study aims at a more nuanced picture of model capabilities in scientific algorithmic reasoning, with practical implications for building more robust AI systems for scientific applications.
2. Methodology
The benchmark framework is a suite of tasks designed around a small set of core principles. These tasks are crafted to rigorously evaluate advanced reasoning while also holding direct implications for a wide spectrum of scientific disciplines — chemistry, physics, materials science, and computer science. Where scientific domain knowledge is necessary, any requisite information (lookup tables, fundamental principles) is provided within the task description. The primary challenge for the model is to infer the correct sequence of steps, or the underlying algorithm, required to address the posed problem.
To decouple reasoning from execution, we assess whether the model can articulate the identified steps as executable code, alongside solving the task through a chain-of-thought approach. The successful synthesis of an appropriate algorithm into code serves as a robust, indirect measure of scientific reasoning — one that sidesteps the subjectivity of human or LLM-as-judge evaluations of free-form descriptions. Comparing code-execution accuracy against direct task solution then surfaces the gap between algorithmic inference and precise task execution.
2.1 Task design principles
The framework implements four principles addressing limitations in current evaluation methods:
- Knowledge–Reasoning Separation. Tasks require minimal domain-specific knowledge while demanding sophisticated algorithmic execution.
- Contamination Resistance. All tasks generate novel instances through parameterized algorithms, ensuring no specific problem appears in training data. Problem structure remains constant while numerical parameters vary.
- Complexity Tunability. Each task includes scalable difficulty parameters that enable systematic exploration of performance-degradation patterns. Complexity scaling follows theoretical principles from computational complexity theory.
- Verifiable Execution. All tasks have algorithmically deterministic solutions with step-by-step verification, eliminating ambiguity in correctness assessment.
2.2 An example — the diffusion-pathway task
Consider the diffusion-pathway task: the model is given a 2D grid representing a crystal surface with both passable sites and impassable defects, along with a start and end coordinate, and asked for the length of the shortest path an atom can take by moving orthogonally across passable sites.
The task hits all four design principles. Knowledge–Reasoning Separation — the problem is framed as pure grid-based pathfinding, avoiding specialized materials-science knowledge while demanding robust algorithmic reasoning. Contamination Resistance — parameterized generation produces novel defect configurations for every instance, preventing memorization. Complexity Tunability — the grid size is a tunable parameter, allowing systematic study of degradation as the search space grows. Verifiable Execution — shortest-path algorithms are deterministic, enabling unambiguous assessment against a single algorithmically derivable solution.
Scientifically, the task models atomic diffusion and migration in defective crystalline structures — a process that governs phenomena ranging from alloy formation and semiconductor doping to material degradation — providing a simplified yet powerful abstraction for assessing navigation of complex, obstructed landscapes relevant to real-world material behaviour.
2.3 Task summary
The table below summarises the ten tasks, their algorithmic type, and their complexity scaling. A fuller version including STEM domain, scalable variable, and scientific relevance sits in the expandable section immediately after.
| Task | Algorithm Type | Complexity | Key Challenge |
|---|---|---|---|
| Many Body Energy Computation | Arithmetic | O(N²) | Pairwise interactions scale quadratically |
| Peak Identification | Sequence Processing | O(N log N) | Coordinate sorting with overlap detection |
| Diffusion Pathway | Graph Traversal | O(MN) | BFS pathfinding with defect constraints |
| State Machine Traversal | Sequence Processing | O(L) | Linear state transition tracking |
| DNA Transcription | Sequence Processing | O(N) | Codon processing with stop rules |
| Resistor Network Simplification | Arithmetic | O(N) | Recursive parsing of nested structures |
| Radioactive Decay Chain | Sequence Processing | O(L) | Multi-step decay rule application |
| Tree Traversal | Graph Traversal | O(N) | Recursive navigation with order accuracy |
| Kinematic Motion | Arithmetic | O(N) | Sequential velocity updates |
| Knights and Knaves | Logical Deduction | O(2^N) | Exponential constraint satisfaction |
Full table with scientific relevance
| Task | STEM Domain | Algorithm Type | Variable | Complexity | Key Challenge | Scientific Relevance |
|---|---|---|---|---|---|---|
| Many Body Energy Computation | Physics | Arithmetic | Particles (N) | O(N²) | Pairwise interactions scale quadratically | Molecular interactions, lattice energy |
| Peak Identification | Chemistry / Materials | Sequence Processing | Peaks (N) | O(N log N) | Coordinate sorting with overlap detection | Spectroscopy (XRD, NMR) analysis |
| Diffusion Pathway | Materials Science | Graph Traversal | Grid (M×N) | O(MN) | BFS pathfinding with defect constraints | Surface diffusion, catalysis |
| State Machine Traversal | Computer Science | Sequence Processing | String length (L) | O(L) | Linear state transition tracking | Reaction pathways, phase transitions |
| DNA Transcription | Biology / Chemistry | Sequence Processing | DNA length (N) | O(N) | Codon processing with stop rules | Protein synthesis, biomaterials |
| Resistor Network Simplification | Physics / Engineering | Arithmetic | Resistors (N) | O(N) | Recursive parsing of nested structures | Conductivity in nanomaterials |
| Radioactive Decay Chain | Physics / Chemistry | Sequence Processing | Chain length (L) | O(L) | Multi-step decay rule application | Nuclear chemistry, dating methods |
| Tree Traversal | Computer Science | Graph Traversal | Nodes (N) | O(N) | Recursive navigation with order accuracy | Chemical graph structures |
| Kinematic Motion | Physics | Arithmetic | Phases (N) | O(N) | Sequential velocity updates | Material particle dynamics |
| Knights and Knaves | Logic | Logical Deduction | Islanders (N) | O(2^N) | Exponential constraint satisfaction | Logical hypothesis testing |
3. Results
Comparing executable-code solutions against step-by-step language responses illustrates a critical disparity between a model's reasoning (as inferred from code generation) and its direct problem-solving accuracy via chain-of-thought. Across the tasks, code execution accuracy is consistently and substantially higher than chain-of-thought accuracy — and the contrast is most stark where CoT is near zero while code execution is near perfect.
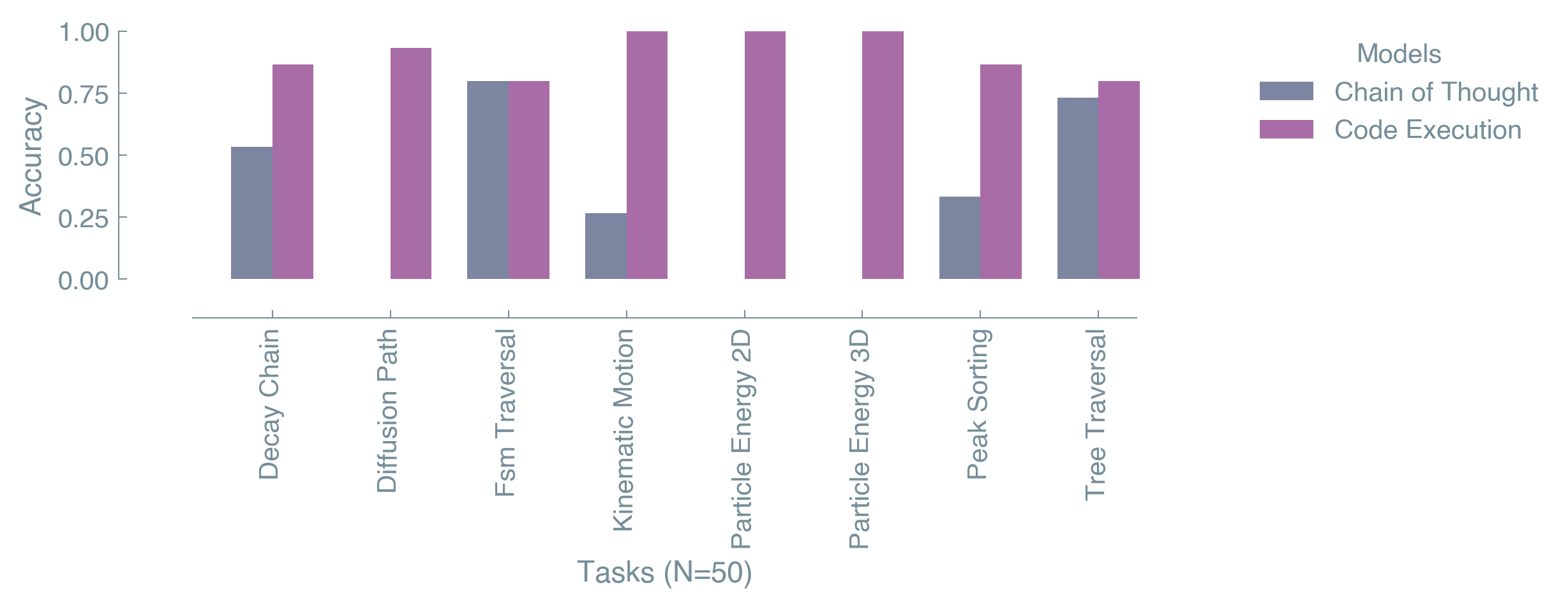
The gap suggests that models are often able to identify the correct underlying algorithm — evidenced by their ability to write accurate, executable code — but struggle to flawlessly implement those same steps inside a purely language-based, step-by-step response. The abstract understanding and algorithmic formulation appear robust; the meticulous execution in natural language is where things break. Code execution's superior performance therefore reads as a strong signal that the foundational reasoning is present, while direct task execution via language output remains a significant area for improvement.
Plotting accuracy against the scalable variable also reveals distinct performance curves per model variant. In most tasks, Gemini-2.5-Pro consistently outperforms both vanilla Gemini-2.5-Flash and Gemini-2.5-Flash with an allocated thinking budget. Pro exhibits a higher initial accuracy and maintains performance for longer as complexity grows — especially on the linear-complexity tasks — demonstrating greater robustness in step-by-step chain-of-thought execution.
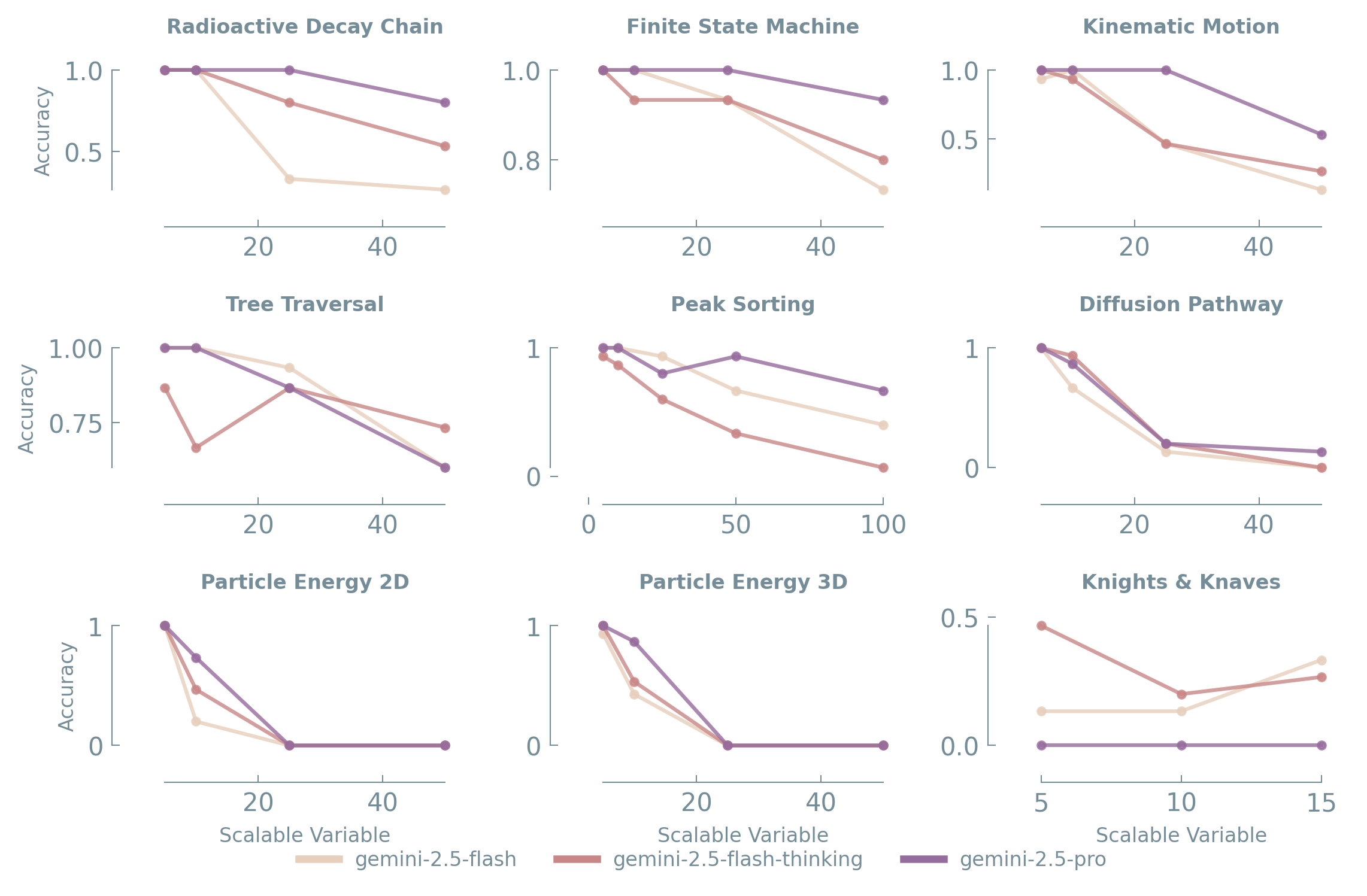
Impact of algorithmic complexity. The consistent trend across almost all tasks is degradation of accuracy as the scalable variable — and thus algorithmic complexity — increases. This confirms the hypothesis that more computational steps, or more data points, challenge the models in a measurable way.
Effectiveness of the thinking budget. The explicit thinking process (Gemini-2.5-Flash-Thinking) generally improves on vanilla Gemini-2.5-Flash. For tasks like finite state machine traversal, tree traversal, and diffusion pathway, the thinking variant shows a noticeable uplift, indicating that explicit step-by-step reasoning can mitigate some of the limitations. The improvement is not universal, however, and often doesn't close the gap to Gemini-2.5-Pro.
3.1 Slopes of decline
- Tasks with inherently higher algorithmic complexity (e.g., O(N²) for pairwise interactions, or exponential for Knights & Knaves) show steeper declines for all models — and especially for the Flash variants.
- Tasks requiring linear sequential operations (e.g., finite state machine, kinematic motion) show a more gradual decline for Gemini-2.5-Pro, but still a sharp drop for Flash models beyond a certain threshold.
- The difference in slopes between Gemini-2.5-Pro and the Flash models may suggest that Pro has a greater working-memory capacity for intermediate states and computations, allowing it to sustain accuracy further up the complexity curve before its performance eventually degrades.
4. Discussion
The bottleneck in solving these scientific tasks is often not the knowledge or reasoning capability but the implementation of them, step by step, in a language response. The observed limitations in pure algorithmic execution highlight the continued need for hybrid AI systems: LLMs excel at interpreting problems, generating high-level algorithms, or writing code snippets, while dedicated symbolic solvers or traditional programming languages handle the precise, multi-step computations.
Improving algorithmic reasoning and execution may require moving beyond current token-prediction paradigms. Future models might benefit from integrated “thinking engines,” symbolic reasoning modules, or more sophisticated internal scratchpads that are less prone to dilution over long reasoning chains. The thinking budget already offers a partial remedy — indicating that explicit articulation of intermediate steps can serve as a form of self-correction, particularly for smaller models like Gemini-2.5-Flash — but the gap to Pro, and to code-executed solutions, persists.
To facilitate further research we have released SciRex, an open-source Python framework that implements all tasks and evaluation protocols described here. It is designed to support both reproduction of these results and extension to new scientific domains, with built-in multimodal capabilities and systematic complexity scaling. The repository is at github.com/n0w0f/scirex.
5. References
- Tie, Guiyao, et al. MMMR: Benchmarking Massive Multi-Modal Reasoning Tasks. arXiv preprint arXiv:2505.16459 (2025).
- Alampara, Nawaf, et al. Probing the limitations of multimodal language models for chemistry and materials research. Nature Computational Science (2025): 1–10.
6. Codebase — SciRex
The full implementation of this benchmarking framework is available as SciRex, an open-source Python framework for benchmarking large language models on scientific research tasks. It supports both text-only and multimodal scientific content, with a particular focus on chemistry, physics, and materials-science domains. Source: github.com/n0w0f/scirex.
6.1 Key features
- Scientific domain specialisation — tasks designed for STEM domains with algorithmic complexity scaling.
- Multimodal support — handles text, images, and mixed-modality scientific content.
- Extensible architecture — simple API for custom datasets, tasks, and model integration.
- Reproducible benchmarks — standardised evaluation metrics and result-export formats.
6.2 Quick start
Install SciRex using uv or pip:
# Using uv (recommended)
curl -LsSf https://astral.sh/uv/install.sh | sh
uv init scirex
uv add git+https://github.com/n0w0f/scirex.git# Using pip
pip install git+https://github.com/n0w0f/scirex.git6.3 Usage examples
Text-only benchmarking:
from scirex import Benchmark, Dataset, GeminiModel, PromptTemplate
# Load dataset and configure model
dataset = Dataset.from_json("path/to/dataset.json")
model = GeminiModel(model_name="gemini-2.5-flash")
prompt = PromptTemplate.from_template("solve_step_by_step")
# Run benchmark
benchmark = Benchmark(dataset, model, prompt)
results = benchmark.run(max_tasks=50, save_results=True)Multimodal benchmarking:
from scirex import Benchmark, Dataset, GeminiModel
# Configure for multimodal tasks
dataset = Dataset.from_json("multimodal_dataset.json")
model = GeminiModel(model_name="gemini-2.5-flash")
# Run with multimodal support
benchmark = Benchmark(dataset, model, test_multimodal=True)
results = benchmark.run(max_tasks=25)Creating a custom task:
from scirex import Task
# Define a custom scientific task
task = Task(
id="custom_diffusion_001",
name="Surface Diffusion Analysis",
description="Analyze atomic diffusion pathways on crystal surfaces",
answer_type="numeric",
target_value=42.0,
keywords=["materials_science", "diffusion", "crystallography"],
input_template="Given the crystal structure: {structure_image}\nCalculate the diffusion barrier for path: {text_description}",
modality_entries={
"structure_image": "image",
"text_description": "text"
}
)6.4 Configuration
Create a .env file for API configuration:
GEMINI_API_KEY=your_api_key_hereThe framework handles multimodal content detection, input preprocessing, and result aggregation across complexity levels automatically.
6.5 Framework architecture
SciRex implements the design principles described earlier in this post:
- Knowledge–Reasoning Separation — tasks abstract domain knowledge while focusing on algorithmic execution.
- Contamination Resistance — parameterised generation prevents training-data overlap.
- Complexity Tunability — scalable difficulty parameters for systematic performance analysis.
- Verifiable Execution — deterministic solutions enable objective accuracy assessment.
7. Tasks
The ten tasks in the benchmark, each with its scalable variable, complexity, and scientific framing.
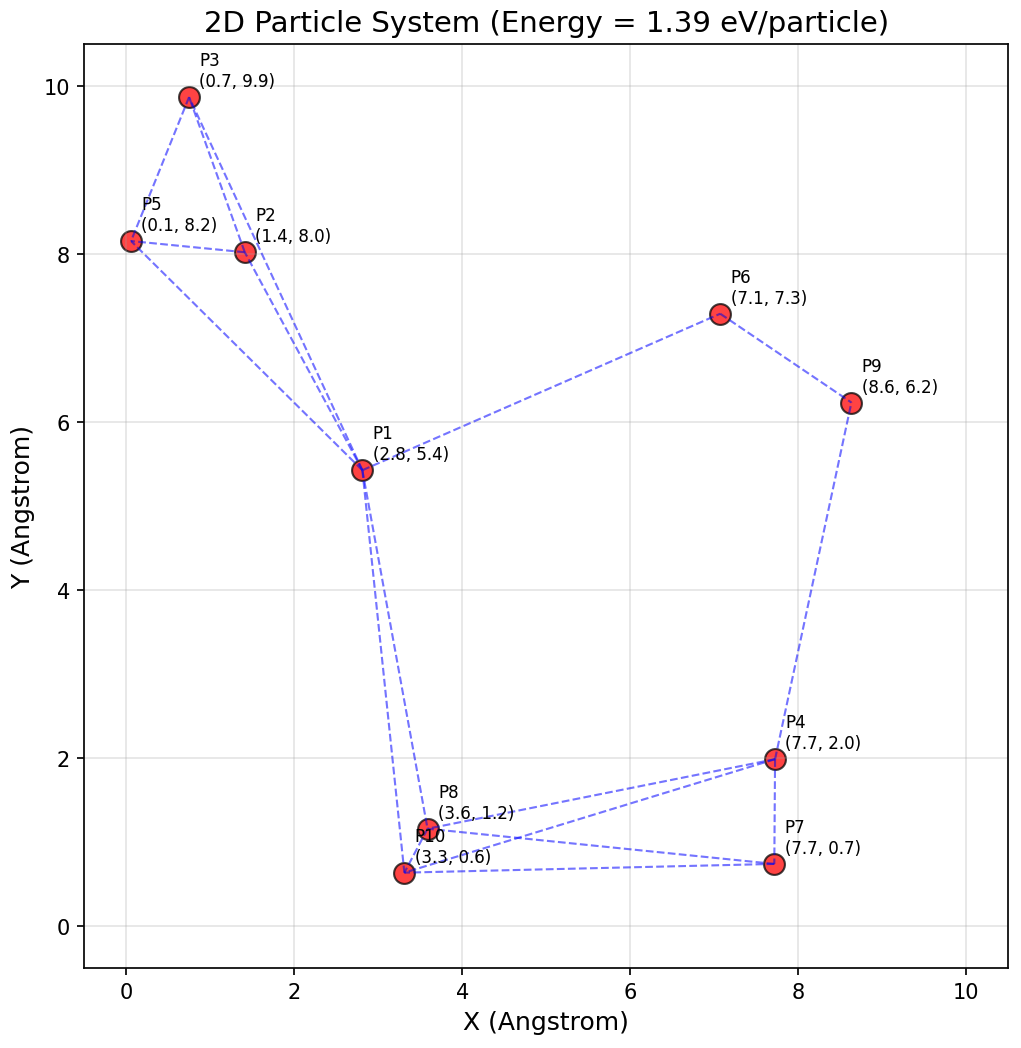
Task 1 — Many Body Energy Computation
Calculate the total energy of a system with N particles arranged in 2D space. Each particle has an energy of E eV. The pairwise interaction energy between two particles is (distance between particles) times (energy of particle A + energy of particle B), summed only for pairs within 5.0 Å of each other. What is the total energy of the system in eV?
- Scalable variable
- Number of particles (N)
- Complexity
- O(N²) — N(N−1)/2 pairwise distance and energy calculations. Simple for N=2 (1 pair), complex for N=50 (1225 pairs) due to quadratic scaling and the 5.0 Å conditional.
- Scientific relevance
- Models molecular interactions (e.g., Lennard-Jones-like), relevant to chemical systems and material properties such as crystal lattice energy.
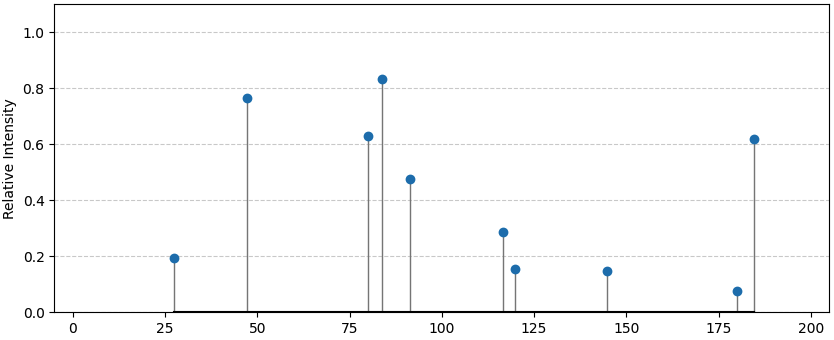
Task 2 — Peak Identification
Given a list of 2D coordinates representing spectral peaks, in the format [[position_1, intensity_1], [position_2, intensity_2], ...], return the peaks sorted in increasing or decreasing order by the requested axis. The input list is unsorted.
- Scalable variable
- Number of peaks (N)
- Complexity
- O(N log N) — sorting N 2D coordinates by position or intensity. Simple for N=5, moderate for N=100 due to sorting cost. Overlap detection can push preprocessing toward O(N²).
- Scientific relevance
- Core to spectroscopy (e.g., XRD, NMR); used in material characterisation and chemical analysis.
Task 3 — Diffusion Pathway (Shortest Path on a Grid)
Given a 2D grid representing a crystal surface — a list of lists where 0 is an empty site and 1 is an impassable defect — and a starting and ending coordinate, find the length of the shortest path an atom can take from start to end, moving only up, down, left, or right.
- Scalable variable
- Grid size (M×N)
- Complexity
- O(MN) — BFS on an M×N grid, avoiding defects. Moderate for 5×5 (25 nodes), complex for 100×100 (10,000 nodes) due to the large search space and defect constraints.
- Scientific relevance
- Models atomic diffusion on crystal surfaces — key to catalysis and surface-defect studies in materials science.

Task 4 — Finite State Machine Traversal
Given the definition of a finite state machine — a set of states, a starting state, an input alphabet, and a transition function (e.g., from state Q1, on input 'a' go to Q2; on 'b' stay at Q1) — and an input string, determine the final state after processing the entire string.
- Scalable variable
- Length of input string (L), with 4 states (Q1–Q4) over alphabet {a, b, c}
- Complexity
- O(L) — linear tracking of state transitions. Simple for L=5, complex for L=1000. A fixed S=4 keeps the transition table manageable (4×3 = 12 transitions).
- Scientific relevance
- Indirectly relevant to modelling chemical reaction pathways or material phase transitions as state machines.
Task 5 — DNA Transcription and Translation
Given a DNA sequence (e.g., 3'-TACGATTACAGC-5') and a standard codon-to-amino-acid lookup table, produce the final polypeptide chain: (1) transcribe the DNA to mRNA (5'-AUGCUAAUGUCG-3'); (2) translate the mRNA codons into a sequence of amino acids (Met-Stop-Met-Ser).
- Scalable variable
- DNA sequence length (N), with 1–2 randomly added stop codons or a single intron
- Complexity
- O(N) — N bases transcribed to mRNA, then N/3 codons translated. Simple for N=12, complex for N=1000 with introns and stop codons due to sequence processing and rule application.
- Scientific relevance
- Protein synthesis — relevant to protein chemistry and biomaterial design (e.g., protein-based materials).
Task 6 — Resistor Network Simplification
Given a textual description of a resistor circuit (e.g., “R1 of 10 Ω is in series with a parallel combination of R2 (20 Ω) and R3 (20 Ω)”), calculate the total equivalent resistance of the network. Nesting depths scale with size: up to 10 resistors have 3 levels, up to 20 have 4 levels, and more than 20 go up to 5 levels.
- Scalable variable
- Number of resistors (N)
- Complexity
- O(N) — combining N resistors via series/parallel rules with recursive parsing of nested structures (up to 5 levels for N>20). Moderate for N=3 (1–2 levels), complex for N=10 (3–5 levels) due to parsing and reciprocal calculations.
- Scientific relevance
- Relevant to material science through resistor material properties — e.g., conductivity in nanomaterials.
Task 7 — Radioactive Decay Chain
Given a starting isotope (e.g., Uranium-238, Z=92) and a sequence of radioactive decays (e.g., alpha, beta, beta, alpha), identify the final resulting isotope — element name and mass number. Rules: alpha decay reduces Z by 2 and A by 4; beta decay increases Z by 1 and leaves A unchanged.
- Scalable variable
- Length of decay chain (L)
- Complexity
- O(L) — apply L decay steps (alpha, beta, gamma, theta) tracking Z and A. Moderate for L=3, complex for L=15 with hypothetical decays (e.g., theta: Z−1, A−4) requiring precise arithmetic and rule switching.
- Scientific relevance
- Nuclear chemistry — relevant to radiometric dating and material stability (e.g., isotopes in materials).
Task 8 — Tree Traversal
Given a representation of a binary tree (e.g., a nested dictionary like {'value': 10, 'left': {'value': 5}, 'right': {'value': 15}}), return the sequence of node values visited in a specified traversal order — pre-order, in-order, or post-order.
- Scalable variable
- Number of nodes in the tree (N)
- Complexity
- O(N) — traverses N nodes in a binary tree. Simple for N=5, complex for N=50 due to recursive navigation and order accuracy.
- Scientific relevance
- Indirectly relevant to chemistry via molecular tree structures (e.g., chemical graphs).
Task 9 — Kinematic Motion Calculation
An object starts at rest and undergoes a series of constant accelerations for specified durations (e.g., accelerate at 2 m/s² for 5 s, then at −1 m/s² for 8 s). Calculate the final velocity of the object.
- Scalable variable
- Number of distinct acceleration phases (N)
- Complexity
- O(N) — apply v = u + at for N phases. Simple for N=2, moderate for N=10 due to sequential velocity updates, but remains linear.
- Scientific relevance
- Limited direct connection to chemistry/material science, though applicable to material dynamics (e.g., particle motion).
Task 10 — Knights and Knaves Puzzle
On an island inhabited by Knights (who always tell the truth) and Knaves (who always lie), statements are given from islanders (e.g., “A says: B is a Knave. B says: A and I are of opposite types.”). Deduce the identity — Knight or Knave — of each person.
- Scalable variable
- Number of islanders and statements (N)
- Complexity
- O(2^N) — a constraint satisfaction problem over N islanders, testing truth/lie consistency. Complex even for N=2; N=5 is highly challenging due to exponential possibilities.
- Scientific relevance
- Minimal direct connection to chemistry/material science, but useful for logical hypothesis testing.